|
|
| The CNRS | LIMSI Directory | |||
 Webmaster
WebmasterSpoken Language Processing Group (TLP)
Groupe TLP - Demos
- A platform for processing multimedia content in Arabic (SAMAR project)
- A system for normalizing French SM
- Emotion detection from Speech
- U-STAR speech recognition and translation
LIMSI is member of the U-STAR consortium. The LIMSI speech and translation systems are used in the VoiceTra 4U App on iTunes.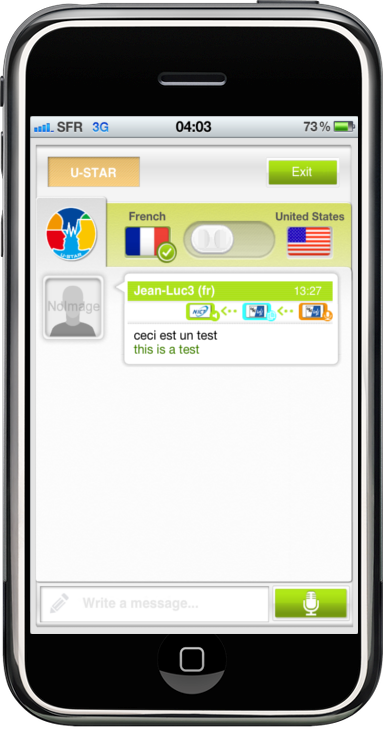
- Audio Indexing
Audio indexing must take into account the specificities of audio data, such as the need to deal with a continuous data stream and an imperfect word transcription. This research aims at combining multilingual speech recognition technology with natural language processing to support a variety of tasks such as automatic structurization of audio data, spoken document retrieval, topic tracking and generation of alerts.
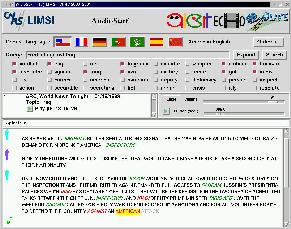
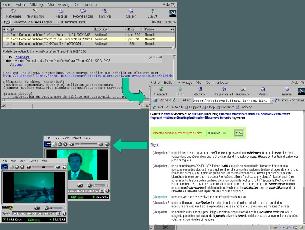
Here are snapshots of the LIMSI AudioSurf system:
- MASK (Multimodal Multimedia Automated Service Kiosk for
train ticket delivery)
Main features: multimodal dialog system (speech and touch screen), higher efficiency (transaction time and user satisfaction) over monomodal solutions, 1500 word vocabulary, speaker independence, signal capture via 2 microphones. The MASK demonstrator can be seen at LIMSI or at the Saint-Lazare train station in Paris (contact us for a demo) - ARISE (Train travel information via the telephone)
Main features: telephone dialog system, 5000 word vocabulary, speaker independence, natural language, mixed initiative dialog, barge-in. If you speak French you can try the demonstrator (still under development) by dialing 08.05.90.22.22. - LVCSR (Large vocabulary continuous speech recognition)
Main features: 65k word vocabulary, speaker independence, spontaneous speech, automatic partitioning and transcription of broadcast news. Radio and television broadcasts contain signal segments of various linguistic and acoustic natures, with abrupt or gradual transitions between segments. The goal of data partitioning is to divide the acoustic signal into homegenous segments, and to associate appropriate labels with the segments. The result of the partitioning process is a set of speech segments with cluster, gender and telephone/wideband labels. The recognition vocabulary contains 65122 words and has a lexical coverage of over 99% on the evaluation test data. The word error rate measured on the nov98 ARPA test data is 13.6%.
 Living with robots
Living with robots Sample (1.1Mo, Realplayer)
Sample (1.1Mo, Realplayer)| | LIMSI home | TLP home | Research Topics | Projects | People | Publications | |
Last modified: Friday,29-November-13 06:35:32 CET