_____________________
L.F. Lamel, J.L. Gauvain, S. Goddijn
Objet
L'objet de cette étude est l'authentification d'un individu à partir d'un échantillon de parole spontanée. Pour effectuer ce travail, nous avons utilisé le corpus Switchboard constitué d'enregistrements de conversations téléphoniques. Afin de comparer les performances d'un système automatique à celles d'auditeurs, des tests perceptifs ont été effectués pour mesurer la capacité d'auditeurs à séparer les locuteurs du corpus.
Description
L'approche habituellement retenue au LIMSI repose sur l'utilisation de
modèles phonétiques, chaque locuteur étant vu comme une source
de phones modélisée par un chaîne de Markov
ergodique. L'authentification du locuteur peut alors être effectuée
avec ou sans connaissance du texte prononcé. Le locuteur est identifié
à partir du signal vocal ![]() en déterminant la fonction de
vraisemblance phonétique
en déterminant la fonction de
vraisemblance phonétique 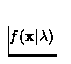 pour chaque locuteur
pour chaque locuteur
![]() connu du système. L'identité du locuteur correspond au
jeu de modèles phonétiques pour lequel la vraisemblance est la
plus grande. Pour vérifier l'identité d'un locuteur (accepter ou
rejeter cette identité), le rapport de vraisemblances
connu du système. L'identité du locuteur correspond au
jeu de modèles phonétiques pour lequel la vraisemblance est la
plus grande. Pour vérifier l'identité d'un locuteur (accepter ou
rejeter cette identité), le rapport de vraisemblances 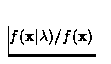 est comparé à un seuil indépendant du
locuteur [1].
est comparé à un seuil indépendant du
locuteur [1].
En préparant notre participation à l'évaluation de mars 1996 organisée par le NIST, nous avons comparé l'approche phonétique à un système utilisant un simple modèle multi-gaussian (GMM). Sur les données du corpus Switchboard, ces deux modèles ont en fait sensiblement les mêmes performances, le modèle GMM nécessitant beaucoup moins de calculs. Afin d'analyser les problèmes liés à ces données, des test perceptifs ont été effectués pour mesurer la capacité d'auditeurs à séparer les locuteurs du corpus [3]. Des échantillons de 3 à 30s ont été sélectionnés pour 20 locuteurs (8 hommes, 12 femmes) qui sont souvent incorrectement identifiés par les systèmes. D'autres échantillons de 24 locuteurs (12 hommes, 12 femmes), avec lesquels les locuteurs de référence sont fréquemment confondus, ont été utilisés comme données d'imposteurs. Deux cent paires d'échantillons ont ainsi été élaborées pour quatre conditions : même locuteur et même conversation, même locuteur et différentes conversations, même locuteur et différents téléphones, et différents locuteurs.
Résultats et perspectives
Sur la table 1 sont donnés les taux d'identification et les
valeurs DCF (coût de décision défini par le NIST,
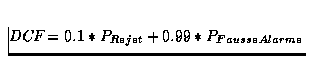 ) obtenus sur les
données de développement pour le modèle GMM et l'approche
phonétique avec ou sans utilisation des transcriptions des
données d'apprentissage. L'utilisation des transcriptions
améliore le taux d'identification pour des
échantillons de 3s et 10s avec 12 modèles phonétiques alors que
le taux est légèrement moindre pour les segments de 30s. Avec 46
modèles phonétiques, le taux d'identification augmente seulement
pour les segments de 10s et 30s. L'utilisation de transcriptions ne
change pas la valeur du DCF. Pour les segments de 30s, le
DCF des modèles phonétiques est réduit de moitié par rapport
au modèle GMM indiquant que l'approche phonétique nécessite des
échantillons plus longs.
) obtenus sur les
données de développement pour le modèle GMM et l'approche
phonétique avec ou sans utilisation des transcriptions des
données d'apprentissage. L'utilisation des transcriptions
améliore le taux d'identification pour des
échantillons de 3s et 10s avec 12 modèles phonétiques alors que
le taux est légèrement moindre pour les segments de 30s. Avec 46
modèles phonétiques, le taux d'identification augmente seulement
pour les segments de 10s et 30s. L'utilisation de transcriptions ne
change pas la valeur du DCF. Pour les segments de 30s, le
DCF des modèles phonétiques est réduit de moitié par rapport
au modèle GMM indiquant que l'approche phonétique nécessite des
échantillons plus longs.
Huit sujets ont participé à un test de type AX pour lequel les deux réponses possibles sont ``même locuteur'' et ``locuteurs différents'' associées à un score de confiance (++,+,-). Les sujets ont commis le plus d'erreurs sur les échantillons d'un même locuteur utilisant différents combinés téléphoniques, puis sur les échantillons provenant de différentes conversations (voir table 2). Les auditeurs ont un taux d'erreur d'environ 40% lorsqu'ils ne sont pas sûrs de leur choix et de 10% lorsqu'ils pensent être certains.
Références
[1] J.L. Gauvain, L.F. Lamel, B. Prouts : ``Experiments with
speaker verification over the telephone,'' ESCA Eurospeech'95,
Madrid, Spain, 1, pp. 651-654, septembre 1995.
[2] S. Goddijn : ``Testing the LIMSI-Algorithm for Speaker
Verification on two Different Corpora,'' Erasmus Project Report,
Utrecht University, The Netherlands, mai 1996.
[3] L. Lamel, J.L. Gauvain : ``Speaker Recognition with the
Switchboard Corpus,'' IEEE ICASSP'97, Munich, mai 1997.
| Gpe Taitement du Langage Parlé | Dpt CHM |  Sommaire
Sommaire
|