_____________________
Objet
Les modèles de langage n-grammes, généralement utilisés dans les systèmes de reconnaissance de la parole, sont basés sur des statistiques de prédiction d'un mot connaissant les n-1 mots précédents. Lorsque les données sont quantitativement insuffisantes, une méthode palliative est de regrouper les mots dans des classes, pour créer des modèles n-classes plus robustes. Jusqu'à présent, nous classions des ensembles de mots par rapport à d'autres ensembles de mots. Ici, nous proposons des classements plus nuancés, en regroupant des mots par rapport à un mot, celui-ci pouvant être à droite ou à gauche des mots classés.
Description
Etant donné la complexité du problème, nous avons
choisi une méthode de Monte Carlo qui, étant donné un nombre
de classes, fixé à l'avance, répartit les mots
dans ces classes en n'autorisant qu'une seule classe par mot. Le
processus est itératif et attribue le nouveau
classement au mot si la perplexité du texte d'apprentissage
PPT<<6>>app, calculée en se limitant à un modèle de Markov
d'ordre 1, décroît. Si on note P(mj/mi) la probabilité
conditionnelle du bigramme-mot {mi mj}, la perplexité s'écrit:
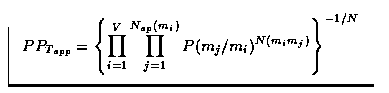

Par la suite, la classe de mi sera appelé Ck et celle de mj, Cq.
L'interaction classe-classe, utilisée jusqu'à présent,
place le mot mi dans une classe Ck, en tenant compte
des nouvelles interactions induites entre cette classe et les autres
classes, que ces classes soit immédiatement avant ou après la classe
Ck.
Nous présentons deux nouveaux types de classement. Le premier,
mot-classe, met chaque mot mj dans une classe Cq, en tenant
compte des mots mi qui peuvent le précéder. La probabilité
P(mj/mi) est
estimée par .
Le second type de
classement, classe-mot, est le cas symétrique du précédent:
chaque mot mi est placé dans une classe Ck, en tenant
compte des mots mj qui peuvent lui succéder. De cette manière
on approxime P(mj/mi) par . Les probabilités
sont estimées
à partir des fréquences des évènements observés dans le texte
d'apprentissage. La perplexité du texte test est calculée
en effectuant une interpolation non linéaire des bigrammes non
observés.
Résultats et perspectives
Les textes utilisés pour la comparaison des modèles
proviennent des transcriptions de
dialogues homme-machine enregistrés au LIMSI, dans le cadre de deux
applications concernant les transports ferroviaires, MASK (Multimodal-Multimedia Automated Service Kiosk)
et RAILTEL. 36 722 phrases ont été utilisées pour l'apprentissage
et 1 107 autres phrases pour le
test.
Les classements ont été testés pour les trois types
d'interaction, en faisant varier le nombre de classes de 50 à
400 (Figure 1). Le modèle classe-mot
présente des valeurs de perplexités inférieures à celles des
deux autres modèles, bien que tous les trois aient une
évolution similaire, convergeant vers la perplexité calculée à
partir du modèle de bigramme-mot. Un échantillon du contenu de quelques
classes est également présenté ci-contre (Figure 2). Il montre
quelques interactions prédominantes qui ont contribuées
aux classements.
Une évaluation de ces trois modèles de langage
dans un système de reconnaissance est en cours au LIMSI.
Elle vise à améliorer les performances en taux de reconnaissance
du système en apportant un modèle de langage plus élabore,
et à limiter la place en mémoire utilisée.
Références
[1] M. Jardino et C. Beaujard : ``Rôle du contexte dans les modèles de langage ``n-classes''. Application et évaluation sur MASK et RAILTEL'', JST FRANCIL97, 1997.
| Gpe Taitement du Langage Parlé | Dpt CHM |  Sommaire
Sommaire
|